I won't get into details of what a microservice architecture is all about. There are plenty of resources on the net that can help you understand this architecture. One good resource is https://microservices.io/ by Chis Richardson.
In my journey to achieving a loosely coupled services based architecture, I initially started with service decomposition and using a shared database. There are a lot of cons to this approach and it creates a single point of failure at runtime but it also creates dependencies to data models and structures especially if you don't segregate boundaries by creating different "databases", "schemas", or "namespaces" in that physically shared database.
There is a pattern called Database per-service that provides a lot of capabilities since each service has its own database server when comes to keep your services independent and achieving greater scalability. There are some alternatives to this approach such as private tables or private schemas per service.
When you end up having a private schema or a private database server for a given microservice however you run into issues with having the need to have read optimized views of data that is not in the services on database server. For example, you have a service that manages membership of a given social web site. In this example, you could represent USER as a service and SITE/ORGANIZATION as another service. When you need to manage membership either USER or SITE/ORGANIZATION service will need to know about the other entity.
In situations like these it is essential to rely on Domain Events. Events represent some state change happening in a given domain. In our above example, a new USER creation can be represented with an event called "UserCreatedEvent". This event can contain simple data attributes such as user's first name, last name, username and when the user was created. This event can then be used by any interested party to update any other services domain database. I use the term domain here to represent a service. Using Domain Driven Design to create microservices are a common architectural pattern.
In this article, I will talk about couple of ways to create an EVENT DRIVEN architecture that will involve AWS KINESIS as the streaming queue.
AWS Kinesis Data Streams is a serverless streaming queue that has low latency that allows components to synchronize data. AWS Kinesis uses shards as a means to distribute data and scale reading of large data sets. It provides robust APIs and SDKs across many programming languages and natively connects to many different AWS Services. You can find all about it in https://aws.amazon.com/kinesis/. Particularly this documentation really explains well all of the key concepts of Kinesis - https://docs.aws.amazon.com/streams/latest/dev/key-concepts.html.
AWS Kinesis provides data retention capabilities. At the time of writing, it provides configurable retention policies to 365 days. The higher the number of days the more it costs. Check out the pricing calculator here.
AWS Kinesis provides KCL and KPL libraries. KCL is consumer library and KPL is provider library. You can modify your microservices components to be consuming or producing applications. If you are using a language that is not supported by AWS Kinesis, you can just create a simple HTTP endpoint in Lambda and use the Lambda function as a producer or consumer application.
In my case, we wanted to abstract certain portions of producing it and wanted to have a longer data retention policies. So instead of allowing all the microservices to directly post and produce messages to Kinesis, we created a simple microservice and called in "event-bus". A single POST endpoint was created allowing all other components and microservices to simply post events to "event-bus". Once event-bus received this information, it can produce it to the Kinesis.
In this set up, there can be many failure. What if "event-bus" is not able to post the event to Kinesis because the AWS region is having an issue. Client to server communication would be severely impacted and client transactions may not complete. Depending on the application, this can cause a lot of revenue loss. Therefore, building segregation between components and reducing dependencies lead to more resilient architecture. One way to handle this is through what's called Transaction Log Tailing.
Different database technologies require different setups to achieve log tailing. Here are some examples..
- MySQL binlog
- Postgres WAL
- AWS DynamoDB table streams
There are tools that can help you easily achieve this though.
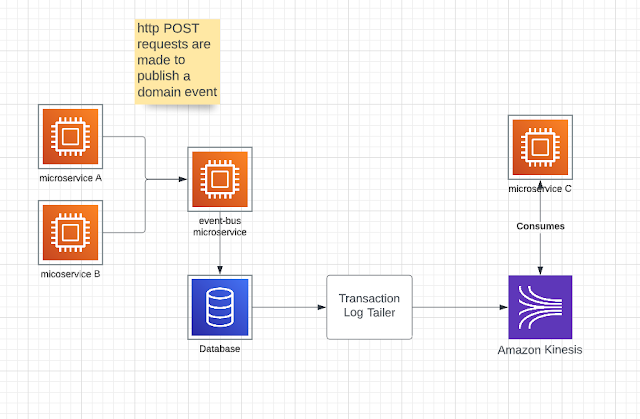
In this example, we have 2 microservices Posting their domain events to an HTTP endpoint. At this point, event-bus microservice, just inserts the event data into a table say called "Events". Once data is committed, event-bus microservice returns a HTTP code of 201 notifying the microservices that their events were saved guaranteeing they will be played. The database can have a retention longer than 365 days and can be easily used to query events as needed by type, entity or any other SQL means.
Things to be Aware
If you end up having 10/20 clients that will read data from all shards, you can consider using AWS Kinesis fan out strategy. Fan out strategy allows you to scale your number of consumers. https://aws.amazon.com/blogs/aws/kds-enhanced-fanout/ this documentation from AWS explains this in detail. However, there is also a limit of how many dedicated fan out streams you can have in a given AWS account. You will be limited to about 20 clients which I believe is a hard limit. Please be aware that there is also extra cost associated with this approach.
If you need to enhance this beyond 20 clients where each client does not get throttled, AWS Kinesis may not be the best approach. In my next article I will consider updating this to using Apache Kafka. AWS has a managed Kafka service called AWS MSK.
Enjoy! Drop your comments, if you have any questions.
Comments